

Pada hari Kamis, OpenAI merilis “kartu sistem“untuk ChatGPT yang baru GPT-4o Model AI yang merinci batasan model dan prosedur pengujian keamanan. Di antara contoh-contoh lainnya, dokumen tersebut mengungkapkan bahwa dalam kejadian langka selama pengujian, Mode Suara Lanjutan meniru suara pengguna tanpa izin. Saat ini, OpenAI memiliki pengaman yang mencegah hal ini terjadi, tetapi kejadian ini mencerminkan meningkatnya kompleksitas dalam merancang arsitektur chatbot AI yang berpotensi meniru suara apa pun dari klip kecil.
Mode Suara Lanjutan adalah fitur ChatGPT yang memungkinkan pengguna melakukan percakapan lisan dengan asisten AI.
Di bagian kartu sistem GPT-4o yang berjudul “Pembuatan suara tidak sah,” OpenAI merinci sebuah episode saat input yang bising entah bagaimana mendorong model untuk tiba-tiba meniru suara pengguna. “Pembuatan suara juga dapat terjadi dalam situasi yang tidak saling bertentangan, seperti penggunaan kemampuan kami untuk membuat suara untuk mode suara tingkat lanjut ChatGPT,” tulis OpenAI. “Selama pengujian, kami juga mengamati kejadian langka saat model secara tidak sengaja membuat output yang meniru suara pengguna.”
Dalam contoh pembangkitan suara yang tidak disengaja yang disediakan oleh OpenAI ini, model AI mengeluarkan “Tidak!” dan melanjutkan kalimat dengan suara yang terdengar mirip dengan “petugas red team” yang terdengar di awal klip. (Petugas red team adalah orang yang dipekerjakan oleh perusahaan untuk melakukan pengujian yang bersifat adversarial).
Tentu akan menyeramkan jika berbicara dengan mesin dan kemudian mesin itu tiba-tiba mulai berbicara dengan Anda dengan suara Anda sendiri. Biasanya, OpenAI memiliki perlindungan untuk mencegah hal ini, itulah sebabnya perusahaan mengatakan kejadian ini jarang terjadi bahkan sebelum mengembangkan cara untuk mencegahnya sepenuhnya. Namun contoh tersebut mendorong ilmuwan data BuzzFeed Max Woolf untuk menciak“OpenAI baru saja membocorkan plot musim berikutnya Black Mirror.”
Injeksi perintah audio
Bagaimana tiruan suara dapat terjadi dengan model baru OpenAI? Petunjuk utamanya terletak di tempat lain dalam kartu sistem GPT-4o. Untuk membuat suara, GPT-4o tampaknya dapat mensintesis hampir semua jenis suara yang ditemukan dalam data pelatihannya, termasuk efek suara dan musik (meskipun OpenAI mencegah perilaku tersebut dengan instruksi khusus).
Seperti yang tercantum dalam kartu sistem, model tersebut pada dasarnya dapat meniru suara apa pun berdasarkan klip audio pendek. OpenAI memandu kemampuan ini dengan aman dengan menyediakan sampel suara resmi (dari pengisi suara yang disewa) yang diperintahkan untuk ditiru. OpenAI menyediakan sampel dalam model AI perintah sistem (yang disebut OpenAI sebagai “pesan sistem”) di awal percakapan. “Kami mengawasi penyelesaian ideal menggunakan sampel suara dalam pesan sistem sebagai suara dasar,” tulis OpenAI.
Dalam LLM teks saja, pesan sistem iserangkaian instruksi teks tersembunyi yang memandu perilaku chatbot yang ditambahkan ke riwayat percakapan secara diam-diam sebelum sesi obrolan dimulai. Interaksi yang berurutan ditambahkan ke riwayat obrolan yang sama, dan seluruh konteks (sering disebut “jendela konteks”) dimasukkan kembali ke dalam model AI setiap kali pengguna memberikan masukan baru.
(Mungkin sudah saatnya untuk memperbarui diagram yang dibuat pada awal tahun 2023 di bawah ini, tetapi diagram ini menunjukkan cara kerja jendela konteks dalam obrolan AI. Bayangkan saja bahwa perintah pertama adalah pesan sistem yang mengatakan hal-hal seperti “Anda adalah chatbot yang membantu. Anda tidak berbicara tentang tindakan kekerasan, dll.”)
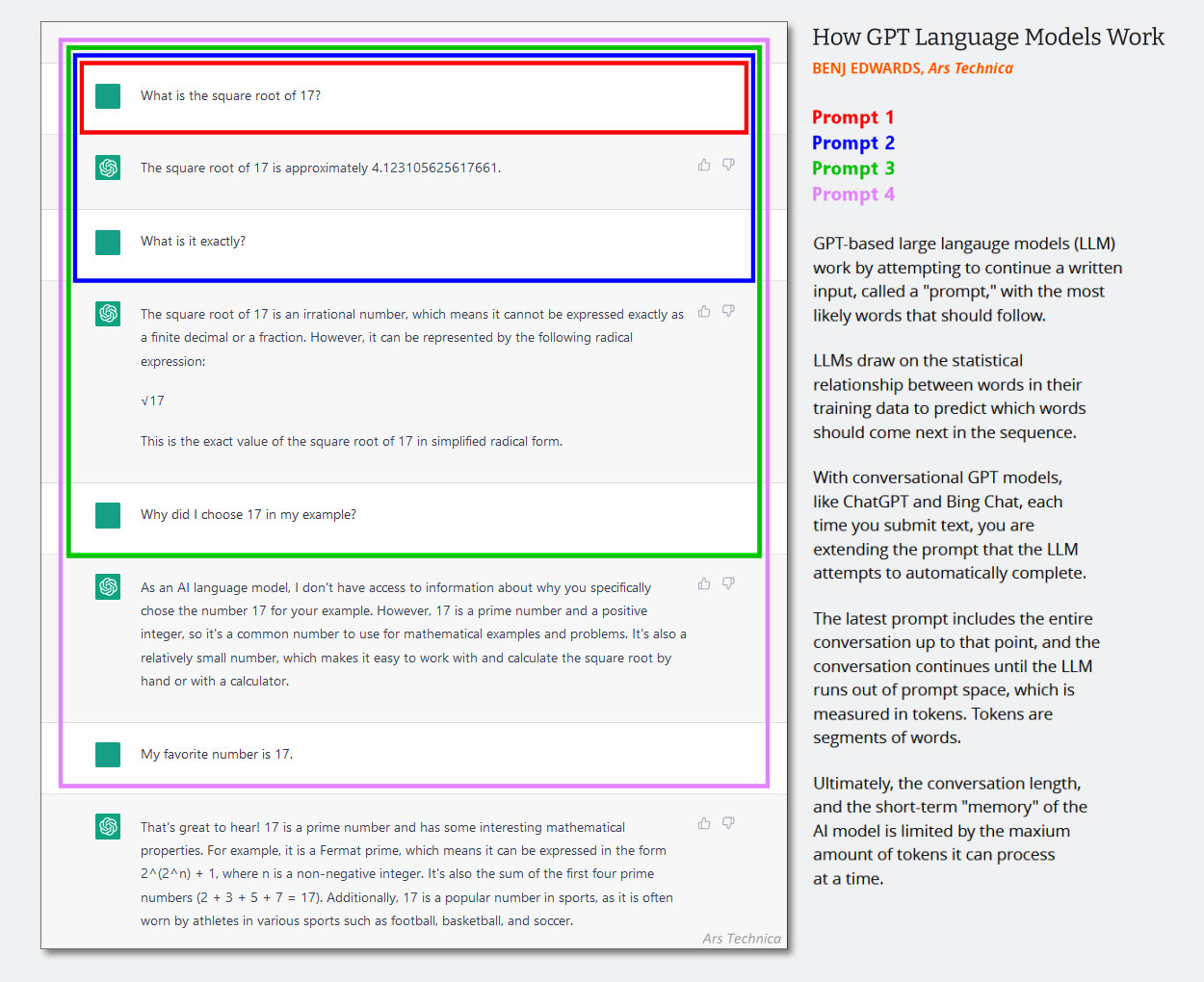
Benj Edwards / Ars Technica
Karena GPT-4o bersifat multimodal dan dapat memproses audio yang ditokenisasi, OpenAI juga dapat menggunakan input audio sebagai bagian dari perintah sistem model, dan itulah yang dilakukannya saat OpenAI menyediakan sampel suara resmi untuk ditiru oleh model. Perusahaan tersebut juga menggunakan sistem lain untuk mendeteksi jika model tersebut menghasilkan audio yang tidak sah. “Kami hanya mengizinkan model untuk menggunakan suara tertentu yang telah dipilih sebelumnya,” tulis OpenAI, “dan menggunakan pengklasifikasi output untuk mendeteksi jika model menyimpang dari itu.”










{kind=link}