
Startup kecerdasan buatan dan spin-off MIT Cairan AI Inc. hari ini meluncurkan serangkaian model AI generatif yang pertama, dan model ini sangat berbeda dari model pesaing karena model tersebut dibuat dengan arsitektur yang secara fundamental baru.
Model-model baru disebut dengan “Liquid Foundation Models,” atau LFM, dan dikatakan memberikan kinerja mengesankan yang setara dengan, atau bahkan lebih unggul, beberapa model bahasa besar terbaik yang ada saat ini.
Startup yang berbasis di Boston ini didirikan oleh tim peneliti dari Massachusetts Institute of Technology, termasuk Ramin Hasani, Mathias Lechner, Alexander Amini, dan Daniela Rus. Mereka disebut-sebut sebagai pionir dalam konsep “jaringan saraf cair”, yang merupakan kelas model AI yang sangat berbeda dari model berbasis Transformator Pra-Terlatih Generatif yang kita kenal dan sukai saat ini, seperti seri GPT OpenAI dan Google. Model Gemini LLC.
Misi perusahaan adalah menciptakan model tujuan umum yang berkemampuan tinggi dan efisien yang dapat digunakan oleh organisasi dari semua ukuran. Untuk melakukan hal tersebut, mereka membangun sistem AI berbasis LFM yang dapat bekerja pada setiap skala, mulai dari edge jaringan hingga penerapan tingkat perusahaan.
Apa itu LFM?
Menurut Liquid, LFM-nya mewakili generasi baru sistem AI yang dirancang dengan mempertimbangkan kinerja dan efisiensi. Mereka menggunakan memori sistem minimal sambil memberikan kekuatan komputasi yang luar biasa, jelas perusahaan.
Mereka didasarkan pada sistem dinamis, aljabar linier numerik, dan pemrosesan sinyal. Hal ini menjadikannya ideal untuk menangani berbagai jenis data berurutan, termasuk teks, audio, gambar, video, dan sinyal.
Liquid AI pertama kali menjadi berita utama pada bulan Desember mengumpulkan $37,6 juta dalam pendanaan awal. Pada saat itu, dijelaskan bahwa LFMnya didasarkan pada arsitektur Liquid Neural Network yang lebih baru yang awalnya dikembangkan di Laboratorium Ilmu Komputer dan Kecerdasan Buatan MIT. LNN didasarkan pada konsep neuron buatan, atau node untuk mentransformasikan data.
Jika model deep learning tradisional memerlukan ribuan neuron untuk melakukan tugas komputasi, LNN dapat mencapai performa yang sama dengan jumlah neuron yang jauh lebih sedikit. Hal ini dilakukan dengan menggabungkan neuron-neuron tersebut dengan formulasi matematis inovatif, sehingga memungkinkannya melakukan lebih banyak hal dengan biaya lebih sedikit.
Perusahaan rintisan ini mengatakan LFM-nya mempertahankan kemampuan beradaptasi dan efisien, yang memungkinkan mereka melakukan penyesuaian real-time selama inferensi tanpa beban komputasi besar yang terkait dengan LLM tradisional. Hasilnya, mereka dapat menangani hingga 1 juta token secara efisien tanpa dampak nyata pada penggunaan memori.
Liquid AI dimulai dengan tiga model saat peluncuran, termasuk LFM-1B, yang merupakan model padat dengan 1,3 miliar parameter, dirancang untuk lingkungan dengan sumber daya terbatas. Yang sedikit lebih bertenaga adalah LFM-3B, yang memiliki 3,1 miliar parameter dan ditujukan untuk penerapan edge, seperti aplikasi seluler, robot, dan drone. Terakhir, ada LFM-40B, yang merupakan model “campuran para ahli” yang jauh lebih kuat dengan 40,3 miliar parameter, yang dirancang untuk diterapkan di server cloud guna menangani kasus penggunaan yang paling kompleks.
Startup ini berpendapat bahwa model-model barunya telah menunjukkan “hasil tercanggih” di sejumlah tolok ukur AI yang penting, dan mereka yakin bahwa model-model barunya akan menjadi pesaing tangguh bagi model AI generatif yang sudah ada seperti ChatGPT.
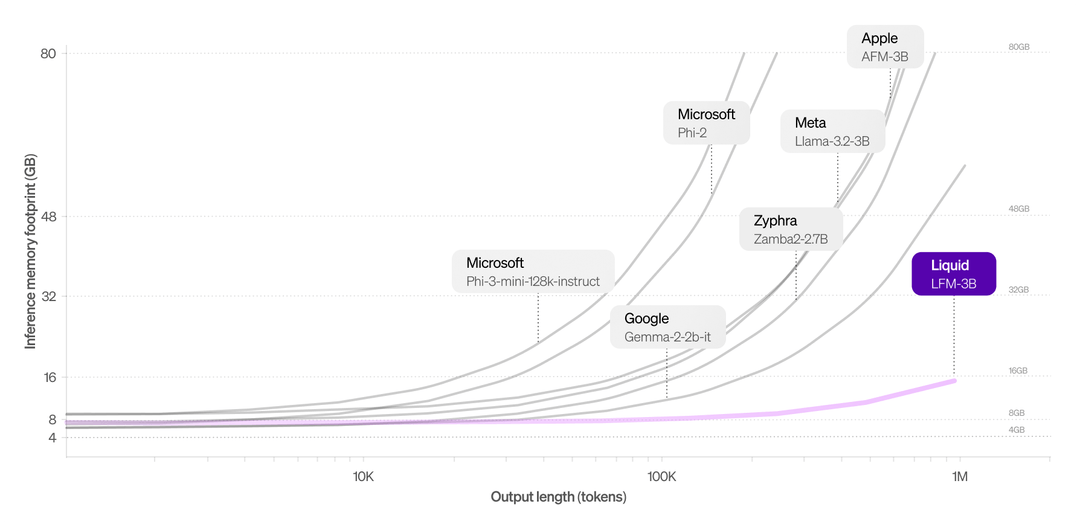
Berbeda dengan LLM tradisional yang mengalami peningkatan tajam dalam penggunaan memori saat melakukan pemrosesan konteks panjang, model LFM-3B secara khusus mempertahankan jejak memori yang jauh lebih kecil (di atas) sehingga menjadikannya pilihan tepat untuk aplikasi yang memerlukan pemrosesan data sekuensial dalam jumlah besar. . Contoh kasus penggunaan mungkin termasuk chatbots dan analisis dokumen, kata perusahaan itu.
Performa yang kuat pada benchmark
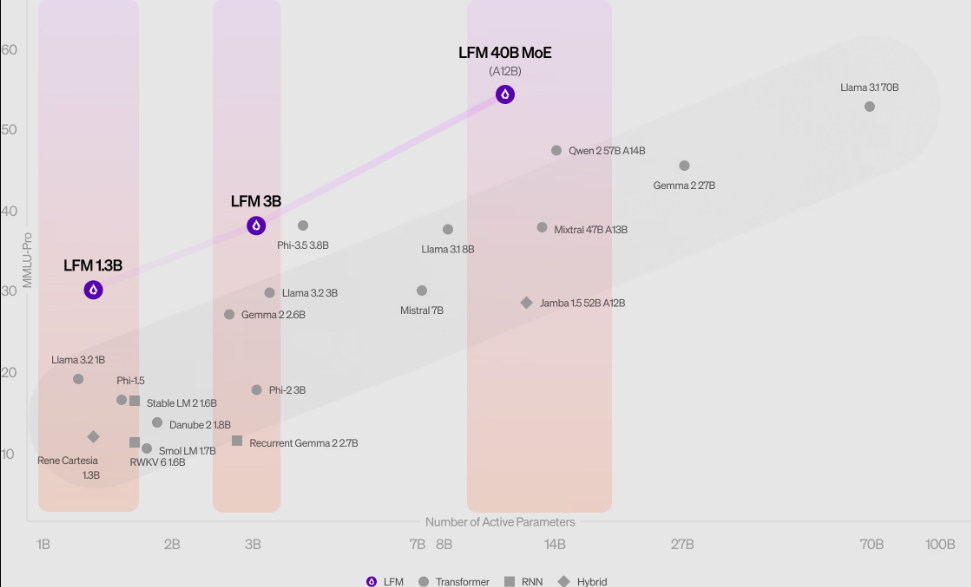
Dalam hal kinerjanya, LFM memberikan beberapa hasil yang mengesankan, dengan LFM-1B mengungguli model berbasis transformator dalam kategori ukuran yang sama. Sementara itu, LFM-3B mampu bersaing dengan model seperti Phi-3.5 dari Microsoft Corp. dan keluarga Llama dari Meta Platforms Inc. Sedangkan untuk LFM-40B, efisiensinya sedemikian rupa sehingga dapat mengungguli model yang lebih besar dengan tetap menjaga keseimbangan tak tertandingi antara kinerja dan efisiensi.
Liquid AI mengatakan model LFM-1B memiliki performa yang sangat mendominasi pada benchmark seperti MMLU dan ARC-C, sehingga menetapkan standar baru untuk model parameter 1B.
Perusahaan ini membuat modelnya tersedia dalam akses awal melalui platform seperti Liquid Playground, Lambda – melalui antarmuka Obrolan dan pemrograman aplikasi – dan Perplexity Labs. Hal ini akan memberikan peluang bagi organisasi untuk mengintegrasikan modelnya ke dalam berbagai sistem AI dan melihat kinerjanya dalam berbagai skenario penerapan, termasuk perangkat edge dan lokal.
Salah satu hal yang sedang dikerjakannya saat ini adalah mengoptimalkan model LFM agar berjalan pada perangkat keras spesifik yang dibuat oleh Nvidia Corp., Advanced Micro Devices Inc., Apple Inc., Qualcomm Inc. dan Cerebras Computing Inc., sehingga pengguna akan dapat memanfaatkannya. bahkan lebih banyak lagi performanya saat mencapai ketersediaan umum.
Perusahaan mengatakan akan merilis serangkaian postingan blog teknis yang mendalami mekanisme setiap model sebelum peluncuran resminya. Selain itu, mereka mendorong kerja sama merah, mengundang komunitas AI untuk menguji LFM mereka hingga batasnya, untuk melihat apa yang bisa dan belum bisa mereka lakukan.
Gambar: SiliconANGLE/Desainer Microsoft
Suara dukungan Anda penting bagi kami dan membantu kami menjaga konten tetap GRATIS.
Satu klik di bawah mendukung misi kami untuk menyediakan konten yang gratis, mendalam, dan relevan.
Bergabunglah dengan komunitas kami di YouTube
Bergabunglah dengan komunitas yang mencakup lebih dari 15.000 pakar #CubeAlumni, termasuk CEO Amazon.com Andy Jassy, pendiri dan CEO Dell Technologies Michael Dell, CEO Intel Pat Gelsinger, dan masih banyak lagi tokoh dan pakar lainnya.
TERIMA KASIH










{kind=link}