
Varians semacam ini—baik dalam proses GSM-Symbolic yang berbeda maupun dibandingkan dengan hasil GSM8K—sangat mengejutkan karena, seperti yang diungkapkan para peneliti, “keseluruhan langkah penalaran yang diperlukan untuk memecahkan suatu pertanyaan tetap sama.” Fakta bahwa perubahan kecil seperti itu menghasilkan hasil yang bervariasi menunjukkan kepada para peneliti bahwa model ini tidak melakukan penalaran “formal” apa pun, melainkan “mencoba melakukan semacam pencocokan pola distribusi, menyelaraskan pertanyaan yang diberikan dan langkah solusi dengan langkah serupa yang terlihat di data pelatihan.”
Jangan terganggu
Namun, varians keseluruhan yang ditunjukkan pada pengujian GSM-Symbolic seringkali relatif kecil dalam skema besar. ChatGPT-4o OpenAI, misalnya, turun dari 95,2 persen akurasi pada GSM8K menjadi 94,9 persen yang masih mengesankan pada GSM-Symbolic. Tingkat keberhasilan tersebut cukup tinggi jika menggunakan salah satu tolok ukur, terlepas dari apakah model itu sendiri menggunakan alasan “formal” di balik layar atau tidak (meskipun akurasi total untuk banyak model turun drastis ketika para peneliti hanya menambahkan satu atau dua langkah logis tambahan ke dalam permasalahan. ).

Contoh yang menunjukkan bagaimana beberapa model menjadi menyesatkan karena informasi tidak relevan yang ditambahkan ke rangkaian benchmark GSM8K.
LLM yang diuji bernasib jauh lebih buruk, ketika peneliti Apple memodifikasi benchmark GSM-Symbolic dengan menambahkan “pernyataan yang tampaknya relevan namun pada akhirnya tidak penting” pada pertanyaan. Untuk kumpulan tolok ukur “GSM-NoOp” ini (kependekan dari “tidak ada operasi”), pertanyaan tentang berapa banyak kiwi yang dipetik seseorang dalam beberapa hari mungkin dimodifikasi untuk menyertakan detail kebetulan bahwa “lima di antaranya (kiwi) sedikit lebih kecil dari rata-rata.”
Menambahkan faktor-faktor ini menyebabkan apa yang para peneliti sebut sebagai “penurunan kinerja yang sangat besar” dalam hal akurasi dibandingkan dengan GSM8K, berkisar antara 17,5 persen hingga 65,7 persen, tergantung pada model yang diuji. Penurunan akurasi yang sangat besar ini menyoroti keterbatasan dalam penggunaan “pencocokan pola” sederhana untuk “mengubah pernyataan menjadi operasi tanpa benar-benar memahami maknanya,” tulis para peneliti.
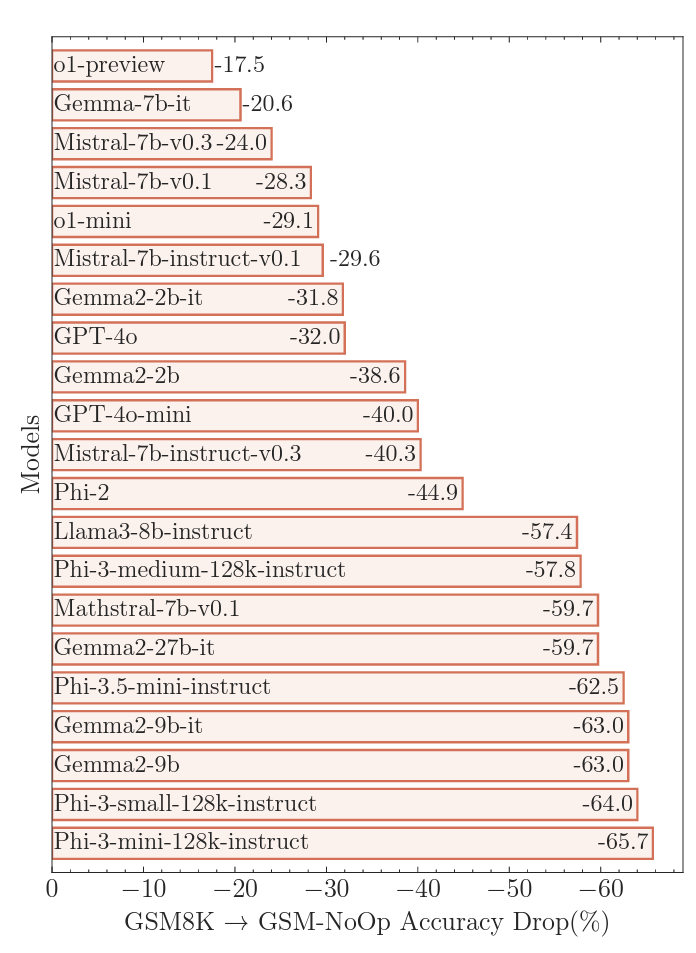
Memasukkan informasi yang tidak relevan ke dalam petunjuk sering kali menyebabkan kegagalan “bencana” bagi sebagian besar LLM yang “beralasan”
Dalam contoh buah kiwi yang lebih kecil, misalnya, sebagian besar model mencoba mengurangi buah yang lebih kecil dari jumlah akhir karena, para peneliti menduga, “kumpulan data pelatihan mereka menyertakan contoh serupa yang memerlukan konversi ke operasi pengurangan.” Ini adalah jenis “kelemahan kritis” yang menurut para peneliti “menunjukkan masalah yang lebih dalam dalam proses penalaran (model)” yang tidak dapat dibantu dengan penyesuaian atau penyempurnaan lainnya.









{kind=link}