

Pada hari Kamis, platform hosting AI Hugging Face terlampaui 1 juta model AI terdaftar untuk pertama kalinya, menandai tonggak sejarah dalam bidang pembelajaran mesin yang berkembang pesat. Model AI adalah program komputer (sering kali menggunakan jaringan saraf) yang dilatih berdasarkan data untuk melakukan tugas tertentu atau membuat prediksi. Platform ini, yang dimulai sebagai aplikasi chatbot pada tahun 2016 sebelum berubah menjadi hub sumber terbuka untuk model AI pada tahun 2020, kini menampung beragam alat untuk pengembang dan peneliti.
Bidang pembelajaran mesin mewakili dunia yang jauh lebih besar dari sekedar model bahasa besar (LLM) seperti yang mendukung ChatGPT. Dalam postingan di X, CEO Hugging Face Clément Delangue menulis tentang bagaimana perusahaannya menampung banyak model AI terkenal, seperti “Llama, Gemma, Phi, Flux, Mistral, Starcoder, Qwen, Stable diffusion, Grok, Whisper, Olmo, Command, Zephyr, OpenELM, Jamba, Yi,” tetapi juga “999.984 lainnya.”
Alasannya, kata Delangue, berasal dari penyesuaian. “Bertentangan dengan kekeliruan '1 model untuk mengatur semuanya',” tulisnya, “model kecil yang terspesialisasi dan dioptimalkan untuk kasus penggunaan Anda, domain Anda, bahasa Anda, perangkat keras Anda, dan secara umum batasan Anda lebih baik. Faktanya , sesuatu yang hanya sedikit orang sadari adalah bahwa terdapat banyak model di Hugging Face yang bersifat pribadi hanya untuk satu organisasi—bagi perusahaan untuk membangun AI secara pribadi, khususnya untuk kasus penggunaan mereka.”
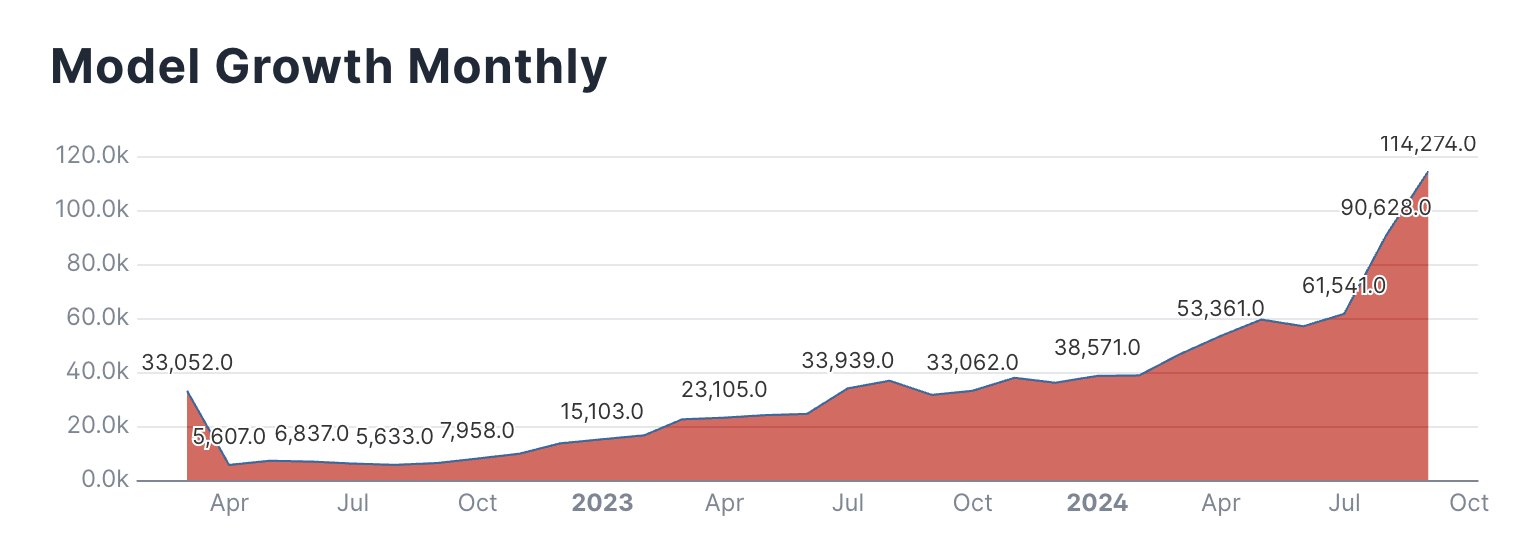
Transformasi Hugging Face menjadi platform AI utama mengikuti percepatan penelitian dan pengembangan AI di industri teknologi. Hanya dalam beberapa tahun, jumlah model yang dihosting di situs ini telah meningkat secara dramatis seiring dengan minat terhadap bidang tersebut. Di X, insinyur produk Hugging Face Caleb Fahlgren memposting grafik model yang dibuat setiap bulan di platform (dan a link ke tangga lagu lain), mengatakan, “Model-modelnya berkembang secara eksponensial dari bulan ke bulan dan bulan September bahkan belum berakhir.”
Kekuatan penyesuaian
Seperti yang ditunjukkan oleh Delangue di atas, banyaknya model pada platform berasal dari sifat kolaboratif platform dan praktik menyempurnakan model yang ada untuk tugas-tugas tertentu. Penyempurnaan berarti mengambil model yang sudah ada dan memberinya pelatihan tambahan untuk menambahkan konsep baru ke jaringan sarafnya dan mengubah cara model tersebut menghasilkan keluaran. Pengembang dan peneliti dari seluruh dunia menyumbangkan hasil mereka, sehingga menghasilkan ekosistem yang besar.
Misalnya, platform ini menampung banyak variasi bobot terbuka Meta Model lama yang mewakili versi berbeda dari model dasar asli, masing-masing dioptimalkan untuk aplikasi tertentu.
Repositori Hugging Face mencakup model untuk berbagai tugas. Menjelajahinya halaman model menunjukkan kategori seperti gambar-ke-teks, jawaban pertanyaan visual, dan jawaban pertanyaan dokumen di bagian “Multimodal”. Dalam kategori “Computer Vision”, terdapat sub-kategori antara lain estimasi kedalaman, deteksi objek, dan pembuatan gambar. Tugas pemrosesan bahasa alami seperti klasifikasi teks dan menjawab pertanyaan juga disajikan, bersama dengan model pembelajaran audio, tabel, dan penguatan (RL).
Memeluk Wajah
Saat diurutkan untuk “unduhan terbanyak,” daftar model Hugging Face mengungkapkan tren model AI mana yang paling berguna bagi banyak orang. Di posisi teratas, dengan keunggulan besar yaitu 163 juta unduhan, adalah Transformator Spektogram Audio dari MIT, yang mengklasifikasikan konten audio seperti ucapan, musik, dan suara lingkungan. Diikuti dengan 54,2 juta unduhan BERT dari Google, model bahasa AI yang belajar memahami bahasa Inggris dengan memprediksi kata-kata terselubung dan hubungan kalimat, sehingga memungkinkannya membantu berbagai tugas bahasa.
Melengkapi lima model AI teratas adalah semua-MiniLM-L6-v2 (yang memetakan kalimat dan paragraf ke representasi vektor padat 384 dimensi, berguna untuk pencarian semantik), Transformator Visi (yang memproses gambar sebagai rangkaian tambalan untuk melakukan klasifikasi gambar), dan OpenAI KLIP (yang menghubungkan gambar dan teks, memungkinkannya mengklasifikasikan atau mendeskripsikan konten visual menggunakan bahasa alami).
Apa pun model atau tugasnya, platform ini terus berkembang. “Saat ini repositori baru (model, kumpulan data, atau ruang) dibuat setiap 10 detik di HF,” tulis Delangue. “Pada akhirnya, akan ada model sebanyak repositori kode dan kami akan siap membantu!”










{kind=link}